Computational experiments
The hydrothermal scheduling problem
To test our proposed variant of SDDP, loglinearSDDP, and compare it to existing variants, we conducted experiments on a hydrothermal scheduling problem from the literature [CITE]. The multistage problem has $T=120$ stages, uses 4 aggregated reservoirs, 95 generators and is based on real data from the Brazilian hydro power system. The hydro inflows into the reservoirs are considered stochastic and modeled by an autoregressive process.
The data for this problem is available in the MSPLib by Bonn Kleiford Seranilla and Nils Löhndorf.
Our computational tests
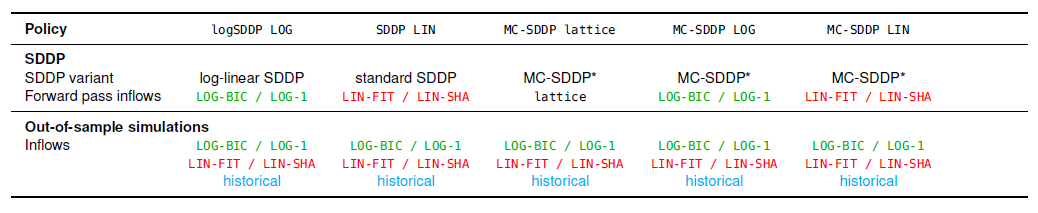
In our paper we compare three different variants of SDDP and the policies that we obtain using these variants.
- loglinearSDDP: Our version of SDDP from this repository. It is suited for uncertainty modeled by log-linear AR processes.
- SDDP with linearized AR processes: Uses standard SDDP from SDDP.jl. Requires to linearize the log-linear AR process beforehand.
- Markov-chain SDDP: Uses the Markov-chain SDDP (MC-SDDP) variant included in SDDP.jl. It requires a Markov-chain approximation (scenario lattice) of the uncertain inflows. This lattice is provided in the MSPLib as well.
Each of these three cases requires slightly different set-ups and function calls due to the differences in the SDDP algorithms as well as the handling of the uncertain data. For this reason there exist three variants of the same functionality several times in our code.
In this documentation, we mostly focus on how to run the loglinearSDDP variant but highlight important differences for the other variants when it feels required.
In addition to SDDP, we used different models for the uncertain data in the RHS:
custom_model(LOG-1 in the paper): log-linear AR process with lag order 1bic_model(LOG-BIC in the paper): log-linear AR process with lag order estimated using the Bayesian Information Criterionfitted_model(LIN-FIT in the paper): linearized AR process with lag order 1 fitted using our codeshapiro_model(LIN-SHA in the paper): linearized AR process with lag order 1 and parameters from the literature- a scenario lattice
latticefor MC-SDDP - historical data
historical
More details on how we fitted these models is provided in model fitting.
We use uncertain data obtained from the log-linear models within loglinearSDDP to train our policy, and uncertain data obtained from the linearized models within standard SDDP to train our policy. For MC-SDDP we use either data from the lattice itself, from log-linear models or from the linearized models.
After running SDDP, we evaluate all obtained policies by running simulations using out-of-sample data from all four stochastic processes as well as historical data.
Note that the code for these simulations (e.g. setting up the uncertainty model and data, simulating new data etc.) has to be catered to the specific variant of the uncertainty, which is why our code contains various slightly different files and methods dealing with simulation. For more details on this, see simulations.
This page was generated using Literate.jl.